Neo4j > Examples > TPC-H Queries
In this example, I will show how we can model the data of a complete B2C application and how to write complex queries on this data model. I am going to use the data model used by the TPC-H benchmark which is shown below.

The idea behind this example is to show how to use Neo4j database to design a data model for a real B2C application. Additionally, we want to see how to write advance SQL queries with joins, grouping and sorting using neo4j Cypher language. I have chosen three queries from the TPCH benchmark that I think will cover most of the common query capabilities of SQL. The chosen queries are Q1, Q3 and Q4 as will be explained in the following sections.
The data used as input for this example is a small set from the data generated using TPCH DBGEN tool. The data is stored as CSV files that correspond to each object in the TPCH benchmark schema shown above (customer, supplier, part, lineitem, order , etc ...). For more details about how to generate the data, please have a look at this blog post.
The complete code of this example can be found in Github along with the steps on how to run it. You can also change the used input data by changing the content of the input files stored in the "data" folder.
Creating the data model
Data model design techniques are explained previously in the data layout section. Based on these techniques, we have modelled the TPCH data model as shown below:
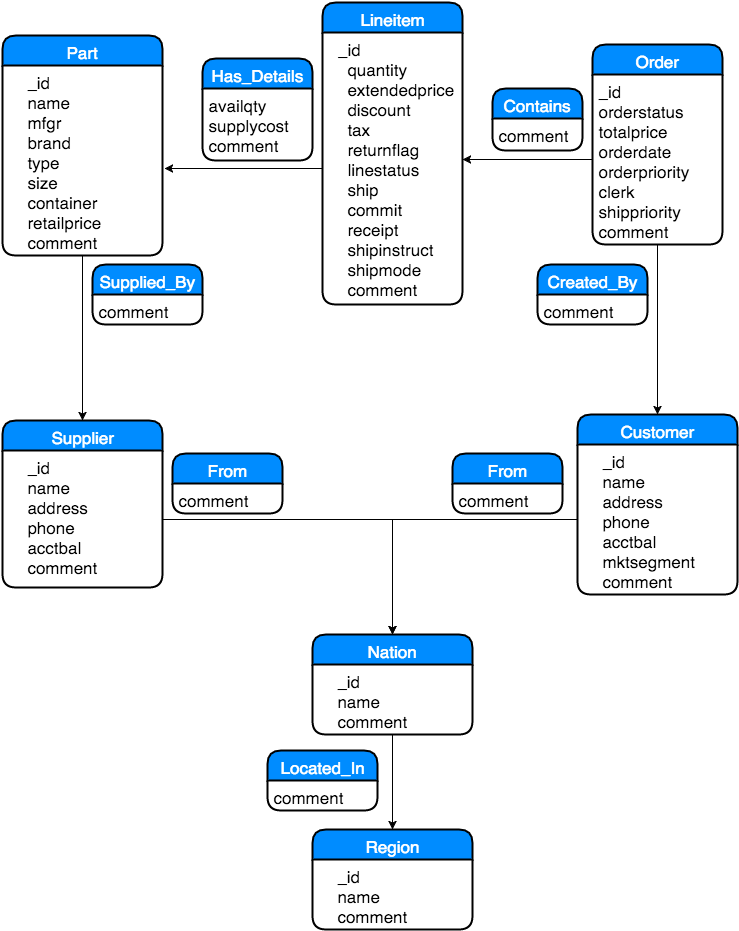
Although we have 8 entities in the TPCH data model, we have created only 7 node's labels (Supplier,Customer,Order,Nation,Region,Lineitem, and Part) since the Partsupp entity is replaced by a relationship. We have created 6 relationship's types (Contains, Created_By, From, Located_in, Has_details and Supplied_By) that represents all the relationships between the different entities in the TPCH model. The Has_details relationship type is the relationship that replaces the Partsupp entity in the TPCH model and we store inside the relationship the availqty and the supplycost values that comes from the Partsupp entity.
Now after defining the Node's labels and relationship's types, we create the actual nodes and relationships and load them with data using a small set of data generated using the TPCH DBGEN tool as explained previously. We store the data as CSV files inside the data folder, then we iterate through the files line by line and create the corresponding nodes and relationships. To see the complete code, please have a look at the TPCHModel.java file.
I will show below the main logic followed and an example code of two functions one to create nodes with label "Lineitem" and the other to create relationships with type "CONTAINS". All other nodes and relationships are created when calling the initialiseData() function.
// Creating all the nodes with label "Lineitem"
void createLineItemNodes() {
File file = new File("src/main/java/org/neo4j/tpcH/data/lineitem.txt");
// Create a unique constraint on the LINENUMBER property
try (Transaction tx = this.graphDb.beginTx()) {
this.graphDb.schema().constraintFor(DynamicLabel.label("Lineitem"))
.assertPropertyIsUnique("LINENUMBER").create();
tx.success();
} catch (Exception e) {
System.out
.println("unique constraint on LINENUMBER creation failed");
System.out.println("Error is " + e.getLocalizedMessage());
}
try (BufferedReader br = new BufferedReader(new FileReader(file))) {
String line;
if (this.graphDb == null) {
System.out.println("graphDb is null");
}
while ((line = br.readLine()) != null) {
// process the line.
String[] lineFields = line.split(Pattern.quote("|"));
// System.out.println(Arrays.toString(lineFields));
try (Transaction tx = this.graphDb.beginTx()) {
Node Lineitem = this.graphDb.createNode(DynamicLabel
.label("Lineitem"));
Lineitem.setProperty("LINENUMBER", lineFields[3]);
Lineitem.setProperty("QUANTITY", Double.valueOf(lineFields[4]));
Lineitem.setProperty("EXTENDEDPRICE", Double.valueOf(lineFields[5]));
Lineitem.setProperty("DISCOUNT", Double.valueOf(lineFields[6]));
Lineitem.setProperty("TAX", Double.valueOf(lineFields[7]));
Lineitem.setProperty("RETURNFLAG", lineFields[8]);
Lineitem.setProperty("LINESTATUS", lineFields[9]);
Lineitem.setProperty("SHIPDATE", format.parse(lineFields[10]).getTime());
Lineitem.setProperty("COMMITDATE", format.parse(lineFields[11]).getTime());
Lineitem.setProperty("RECEIPTDATE", format.parse(lineFields[12]).getTime());
Lineitem.setProperty("SHIPINSTRUCT", lineFields[13]);
Lineitem.setProperty("SHIPMODE", lineFields[14]);
Lineitem.setProperty("COMMENT", lineFields[15]);
System.out.println("Lineitem node with LINENUMBER: "
+ lineFields[0] + " have been created");
tx.success();
} catch (Exception e) {
System.out.println("Lineitem node with LINENUMBER: "
+ lineFields[0] + " creation failed");
System.out.println("Error is " + e.getLocalizedMessage());
}
}
} catch (FileNotFoundException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
As seen from the code above, we first create a unique constraint on the LINENUMBER property for all the nodes with the "Lineitem" label. This constraint is needed to make sure that we aren't creating the same node twice. Then we iterate through the Lineitem CSV file and create a new node with label "Lineitem" for each line in the file. Note that we first create a transaction before creating each node or when creating the unique constraint and commit the transaction at the end if no error was raised.
We do the same as the function above to create nodes for all other node's labels (Supplier,Customer,Order,Nation,Region, and Part). The functions are createCustomerNodes(), createSupplierNodes(), createNationNodes(), createOrderNodes(), createPartNodes() and createRegionNodes().
To create the CONTAINS relationships as an example, we iterate through the Lineitem CSV file. Then for each line we get the order node that has the ORDERKEY as a property inside the node. In the same way, we get the order node that has the LINENUMBER as a property inside the node. Finally we create a relationship that starts from the order node and ends at the lineitem node and make sure that this relationship doesn't already exist to prevent creating the same relationship twice. The code is shown below:
void createContainsRelationship() {
File file = new File("src/main/java/org/neo4j/tpcH/data/lineitem.txt");
try (BufferedReader br = new BufferedReader(new FileReader(file))) {
String line;
if (this.graphDb == null) {
System.out.println("graphDb is null");
}
while ((line = br.readLine()) != null) {
// process the line.
String[] lineFields = line.split(Pattern.quote("|"));
// System.out.println(Arrays.toString(lineFields));
try (Transaction tx = this.graphDb.beginTx()) {
Node lineitemNode = this.graphDb.findNode(
DynamicLabel.label("Lineitem"), "LINENUMBER",
lineFields[3]);
Node orderNode = this.graphDb.findNode(
DynamicLabel.label("Order"), "ORDERKEY",
lineFields[0]);
Iterable<Relationship> orderRelationships = orderNode
.getRelationships();
Iterator<Relationship> orderRelationshipsIterator = orderRelationships
.iterator();
boolean relExists = false;
while (orderRelationshipsIterator.hasNext()) {
Relationship rel = orderRelationshipsIterator.next();
if (rel.getEndNode().equals(lineitemNode)) {
relExists = true;
}
}
if (!relExists) {
orderNode.createRelationshipTo(lineitemNode,
RelTypes.CONTAINS);
System.out
.println("CONTAINS relationship have been created");
}
tx.success();
} catch (Exception e) {
System.out.println("CONTAINS relationship creation failed");
System.out.println("Error is " + e.getLocalizedMessage());
}
}
} catch (FileNotFoundException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
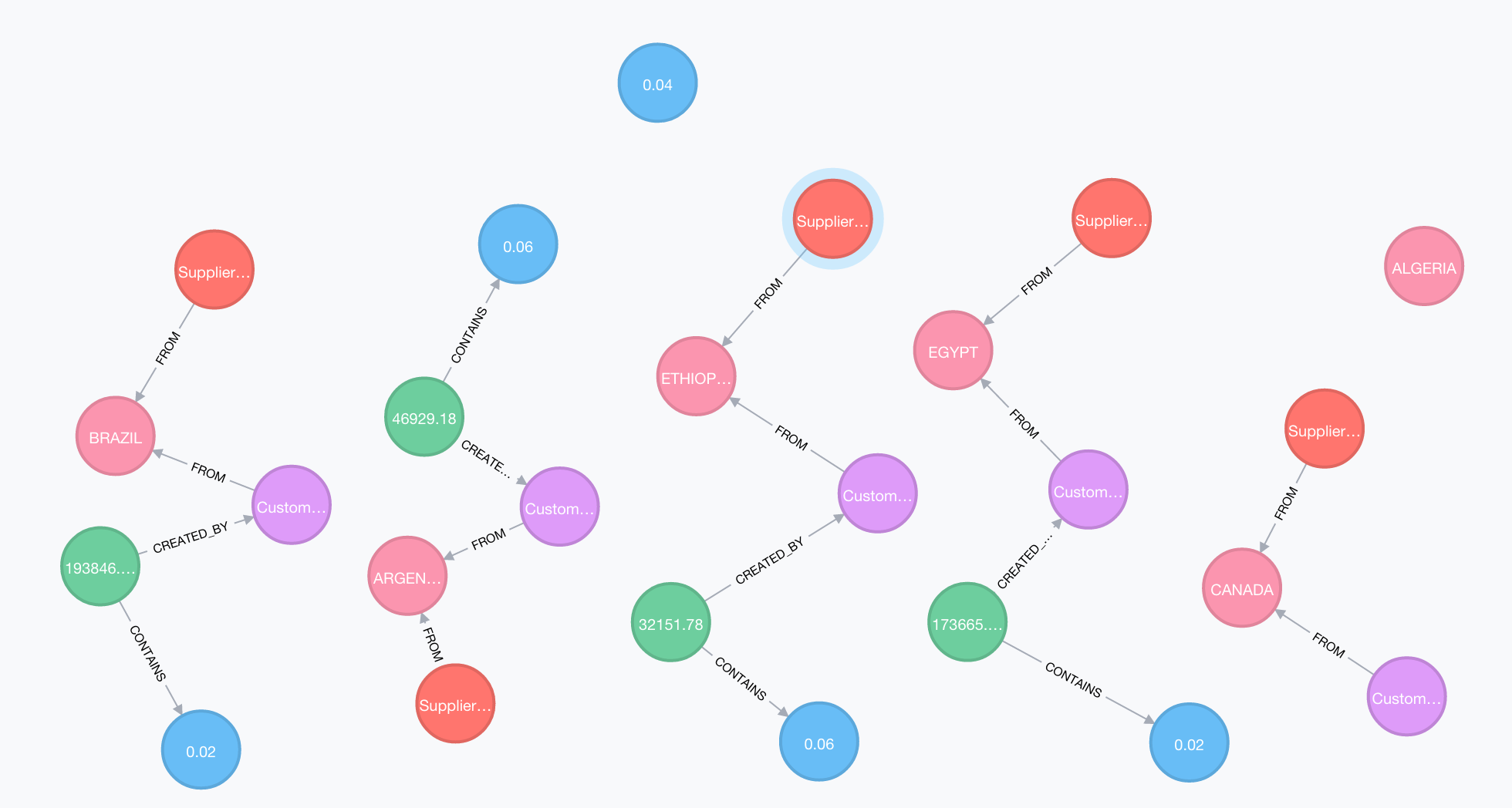
After creating all the nodes and relationships, it will look like the below:
Now after we have our data model ready, we can try to run queries on it. As mentioned before, we have chosen three queries from the TPCH benchmarks to try them in Neo4j as will be shown in the following sections.
Pricing Summary Report Query (Q1)
This query is used to report the amount of billed, shipped and returned items. The SQL query is shown below:
select
l_returnflag,
l_linestatus,
sum(l_quantity) as sum_qty,
sum(l_extendedprice) as sum_base_price,
sum(l_extendedprice*(1-l_discount)) as sum_disc_price,
sum(l_extendedprice*(1-l_discount)*(1+l_tax)) as sum_charge,
avg(l_quantity) as avg_qty,
avg(l_extendedprice) as avg_price,
avg(l_discount) as avg_disc,
count(*) as count_order
from
lineitem
where
l_shipdate <= date '1998-12-01' - interval '[DELTA]' day (3)
group by
l_returnflag,
l_linestatus
order by
l_returnflag,
l_linestatus;
Writing a similar query in Neo4j using Cypher is simple as shown below:
MATCH (item:Lineitem)
WHERE item.SHIPDATE <= 912524220000
RETURN item.RETURNFLAG,item.LINESTATUS,sum(item.QUANTITY) AS sum_qty, sum(item.EXTENDEDPRICE) AS sum_base_price, sum(item.EXTENDEDPRICE*(1-item.DISCOUNT)) AS sum_disc_price,sum(item.EXTENDEDPRICE*(1-item.DISCOUNT)*(1+item.TAX)) AS sum_charge,avg(item.QUANTITY) AS avg_qty, avg(item.EXTENDEDPRICE) AS avg_price, avg(item.DISCOUNT) AS avg_disc
ORDER BY item.RETURNFLAG, item.LINESTATUS
Basically, we are searching all the nodes that are having the "Lineitem" label, filter the results using the shipdate property of the node and return only the fields that are needed in the original SQL query. You can also easily use mathematical operations on the returned fields exactly as we do with SQL and use the built-in aggregate function of Neo4j such as min, max, sum, avg, and count. The aggregation is done automatically in Cypher and there is no need to provide a group by statement. Sorting is done using the ORDER BY statement exactly as we use it in SQL. The only difference is that the Cypher language has no date support, therefore we have stored the date properties as long value representing the Epoch time. When you store the date using the Epoch long value, we will be able to run range queries on the property as we have done above.
The complete implementation of the API call that will retrieve the results for Q1 is shown below:
@GET
@Path("/q1")
@Timed
@ApiOperation(value = "get result of TPCH Q1 using this model", notes = "TPCH Queries", response = String.class)
@ApiResponses(value = {@ApiResponse(code = 500, message = "internal server error !")})
public String getQ1Results() {
Result result = null;
try {
try (Transaction trans = this.graphDb.beginTx()) {
String query1 = "MATCH (item:Lineitem)\n" +
"WHERE item.SHIPDATE <= " + format.parse("1998-12-01").getTime() + " \n" +
"RETURN item.RETURNFLAG,item.LINESTATUS,sum(item.QUANTITY) AS sum_qty, sum(item.EXTENDEDPRICE) AS sum_base_price, sum(item.EXTENDEDPRICE*(1-item.DISCOUNT)) AS sum_disc_price,\n" +
"sum(item.EXTENDEDPRICE*(1-item.DISCOUNT)*(1+item.TAX)) AS sum_charge,avg(item.QUANTITY) AS avg_qty, avg(item.EXTENDEDPRICE) AS avg_price, avg(item.DISCOUNT) AS avg_disc\n" +
"ORDER BY item.RETURNFLAG, item.LINESTATUS";
result = this.graphDb
.execute(query1);
trans.success();
}
return result.resultAsString();
} catch (Exception e) {
LOGGER.log(Level.SEVERE,
"internal server error !" + e.getLocalizedMessage());
final String shortReason = "internal server error !";
Exception cause = new IllegalArgumentException(shortReason);
throw new WebApplicationException(cause,
javax.ws.rs.core.Response.Status.INTERNAL_SERVER_ERROR);
}
}
A sample result of the above query is shown below:

Shipping Priority Query (Q3)
This query is used to get the 10 unshipped orders with the highest value. In order to do that, the query joins three tables (customer, order and lineitem) as shown below:
select
l_orderkey,
sum(l_extendedprice*(1-l_discount)) as revenue,
o_orderdate,
o_shippriority
from
customer,
orders,
lineitem
where
c_mktsegment = '[SEGMENT]'
and c_custkey = o_custkey
and l_orderkey = o_orderkey
and o_orderdate < date '[DATE]'
and l_shipdate > date '[DATE]'
group by
l_orderkey,
o_orderdate,
o_shippriority
order by
revenue desc,
o_orderdate;
Writing a similar Cypher query for the above SQL is also simple as shown below:
MATCH (item:Lineitem) <-[:CONTAINS]- (order:Order ) -[:CREATED_BY]-> (customer:Customer)
WHERE order.ORDERDATE < 912524220000 AND item.SHIPDATE > 631205820000 AND customer.MKTSEGMENT = 'AUTOMOBILE'
RETURN order.ORDERKEY, sum(item.EXTENDEDPRICE*(1-item.DISCOUNT)) AS REVENUE, order.ORDERDATE, order.SHIPPRIORITY
ORDER BY REVENUE DESC, order.ORDERDATE
As we can see above, representing relationships and joins in Cypher is very simple where we just want to use the MATCH statement (MATCH (item:Lineitem) <-[:CONTAINS]- (order:Order ) -[:CREATED_BY]-> (customer:Customer)). We are searching for any node that have the "Order" label and is connected to another node with label "Lineitem" by a relationship with type "Contains". Then we filter the results by the order.ORDERDATE, item.SHIPDATE and customer.MKTSEGMENT using the WHERE statement. Aggregation and ordering is done in a similar way like Q1.
The complete implementation of the API call that will retrieve the results for Q3 is shown below:
@GET
@Path("/q3")
@Timed
@ApiOperation(value = "get result of TPCH Q3 using this model", notes = "TPCH Queries", response = String.class)
@ApiResponses(value = {@ApiResponse(code = 500, message = "internal server error !")})
public String getQ3Results() {
Result result = null;
try {
try (Transaction trans = this.graphDb.beginTx()) {
String query3 = "MATCH (item:Lineitem) <-[:CONTAINS]- (order:Order ) -[:CREATED_BY]-> (customer:Customer)\n" +
"WHERE order.ORDERDATE < 912524220000 AND item.SHIPDATE > 631205820000 AND customer.MKTSEGMENT = 'AUTOMOBILE' \n" +
"RETURN order.ORDERKEY, sum(item.EXTENDEDPRICE*(1-item.DISCOUNT)) AS REVENUE, order.ORDERDATE, order.SHIPPRIORITY\n" +
"ORDER BY REVENUE DESC, order.ORDERDATE";
result = this.graphDb
.execute(query3);
trans.success();
}
return result.resultAsString();
} catch (Exception e) {
LOGGER.log(Level.SEVERE,
"internal server error !" + e.getLocalizedMessage());
final String shortReason = "internal server error !";
Exception cause = new IllegalArgumentException(shortReason);
throw new WebApplicationException(cause,
javax.ws.rs.core.Response.Status.INTERNAL_SERVER_ERROR);
}
}
If you call the above API, you will get a reply like the one shown below:

Order Priority Checking Query (Q4)
This query is used to see how well the order priority system is working and gives indication of the customer satisfaction. The SQL query is shown below:
select
o_orderpriority,
count(*) as order_count
from
orders
where
o_orderdate >= date '[DATE]'
and o_orderdate < date '[DATE]' + interval '3' month
and exists (
select
*
from
lineitem
where
l_orderkey = o_orderkey
and l_commitdate < l_receiptdate
)
group by
o_orderpriority
order by
o_orderpriority;
The above query can be represented in Cypher as shown below:
MATCH (order:Order) -[:CONTAINS]-> (item:Lineitem)
WHERE item.COMMITDATE < item.RECEIPTDATE AND order.ORDERDATE >= 631205820000 AND order.ORDERDATE < 912524220000
RETURN order.ORDERPRIORITY, count(*) AS ORDER_COUNT
ORDER BY order.ORDERPRIORITY
So we have represented the join part between the Lineitem entity and the Order entity using the MATCH clause (MATCH (order:Order) -[:CONTAINS]-> (item:Lineitem)) so that we search for any node having the "Lineitem" label that is connected to a node with the "Order" label by a relationship with type "CONTAINS". Then we filter the results using the item.COMMITDATE and the order.ORDERDATE. Finally we return only the fields that we require and sort the data using the ORDER BY clause.
The complete implementation of the API call that will retrieve the results for Q4 is shown below:
@GET
@Path("/q4")
@Timed
@ApiOperation(value = "get result of TPCH Q4 using this model", notes = "TPCH Queries", response = String.class)
@ApiResponses(value = {@ApiResponse(code = 500, message = "internal server error !")})
public String getQ4Results() {
Result result = null;
try {
try (Transaction trans = this.graphDb.beginTx()) {
String query4 = "MATCH (order:Order) -[:CONTAINS]-> (item:Lineitem) \n" +
"WHERE item.COMMITDATE < item.RECEIPTDATE AND order.ORDERDATE >= 631205820000 AND order.ORDERDATE < 912524220000\n" +
"RETURN order.ORDERPRIORITY, count(*) AS ORDER_COUNT\n" +
"ORDER BY order.ORDERPRIORITY";
result = this.graphDb
.execute(query4);
trans.success();
}
return result.resultAsString();
} catch (Exception e) {
LOGGER.log(Level.SEVERE,
"internal server error !" + e.getLocalizedMessage());
final String shortReason = "internal server error !";
Exception cause = new IllegalArgumentException(shortReason);
throw new WebApplicationException(cause,
javax.ws.rs.core.Response.Status.INTERNAL_SERVER_ERROR);
}
}
If you call the above API, you will get results as shown below:
